Lowest Common Ancestor (LCA)
前言
在此章節中,我們會介紹經典的最近共同祖先(LCA)問題且整理幾種常見的尋找 LCA 的方法。此外也會提及 LCA 問題與另一經典問題(Range Minimum Query)之間的轉化。
定義
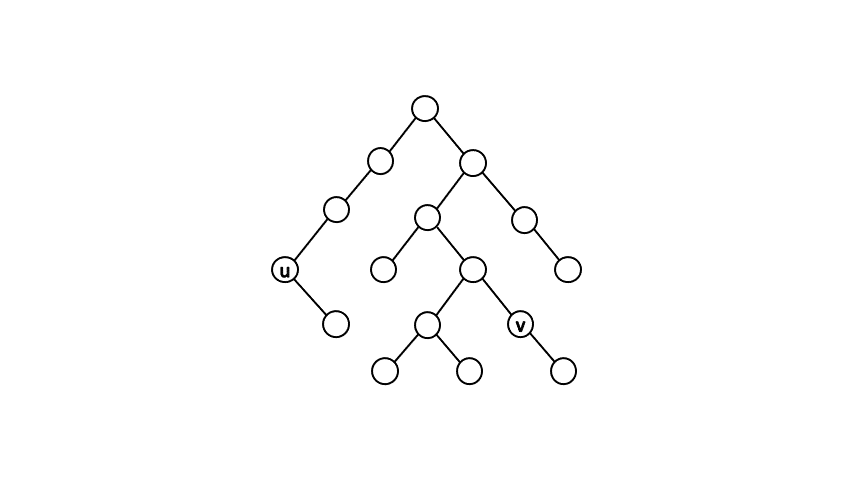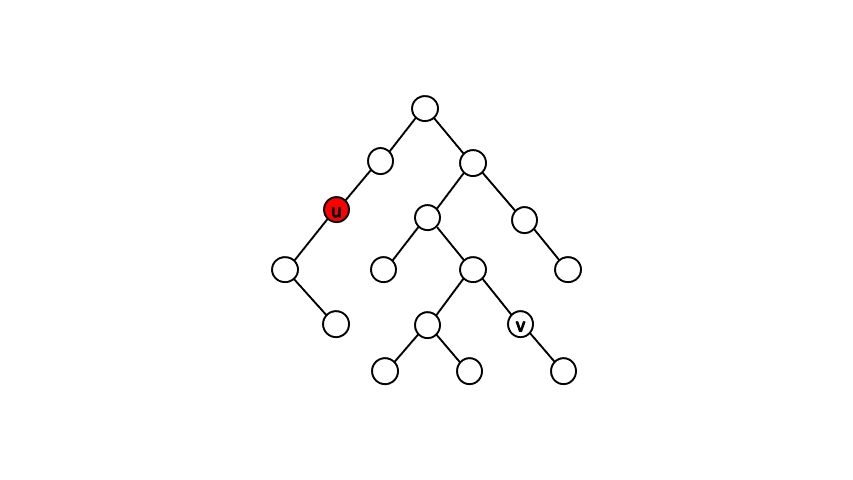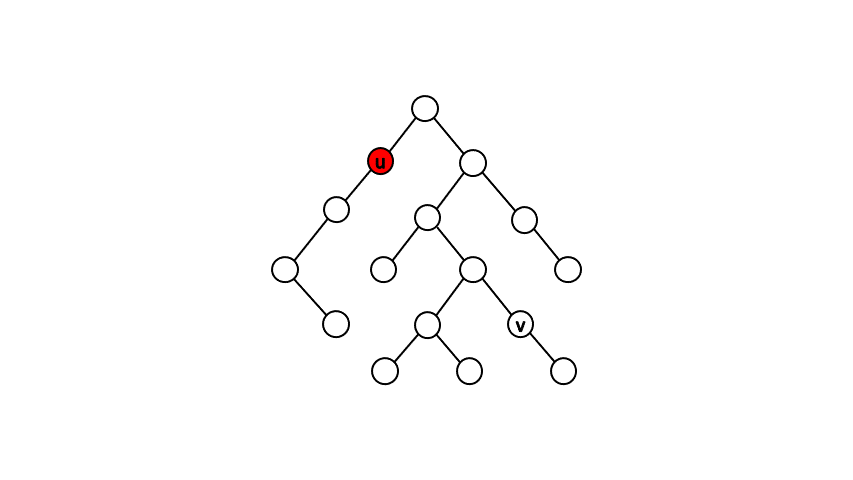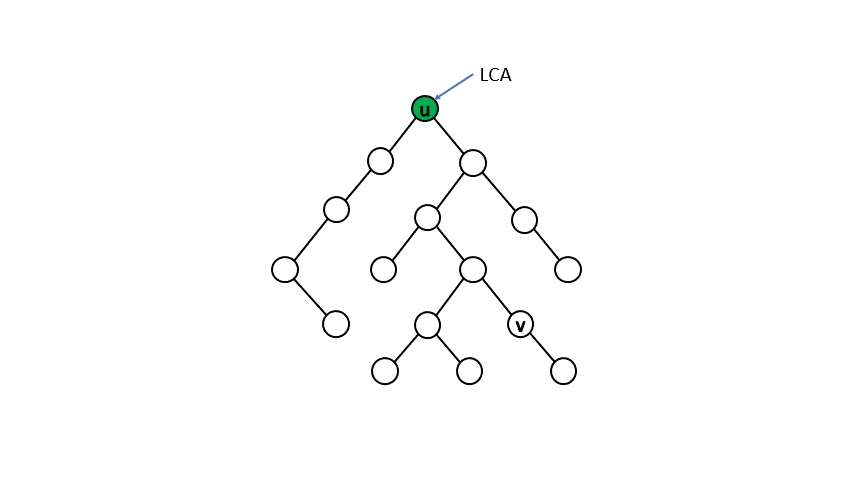
給定一棵有 \( N \) 個節點的有根樹,對於樹中任一點對 \( (u,\ v) \),其最近共同祖先 \( LCA(u,\ v) \) 為同為點 \( u \) 和點 \( v \) 的祖先中深度最深的點,這邊我們定義點的深度為點到根路徑上所經過的邊數且自己為自己的祖先(為了方便之後討論)。
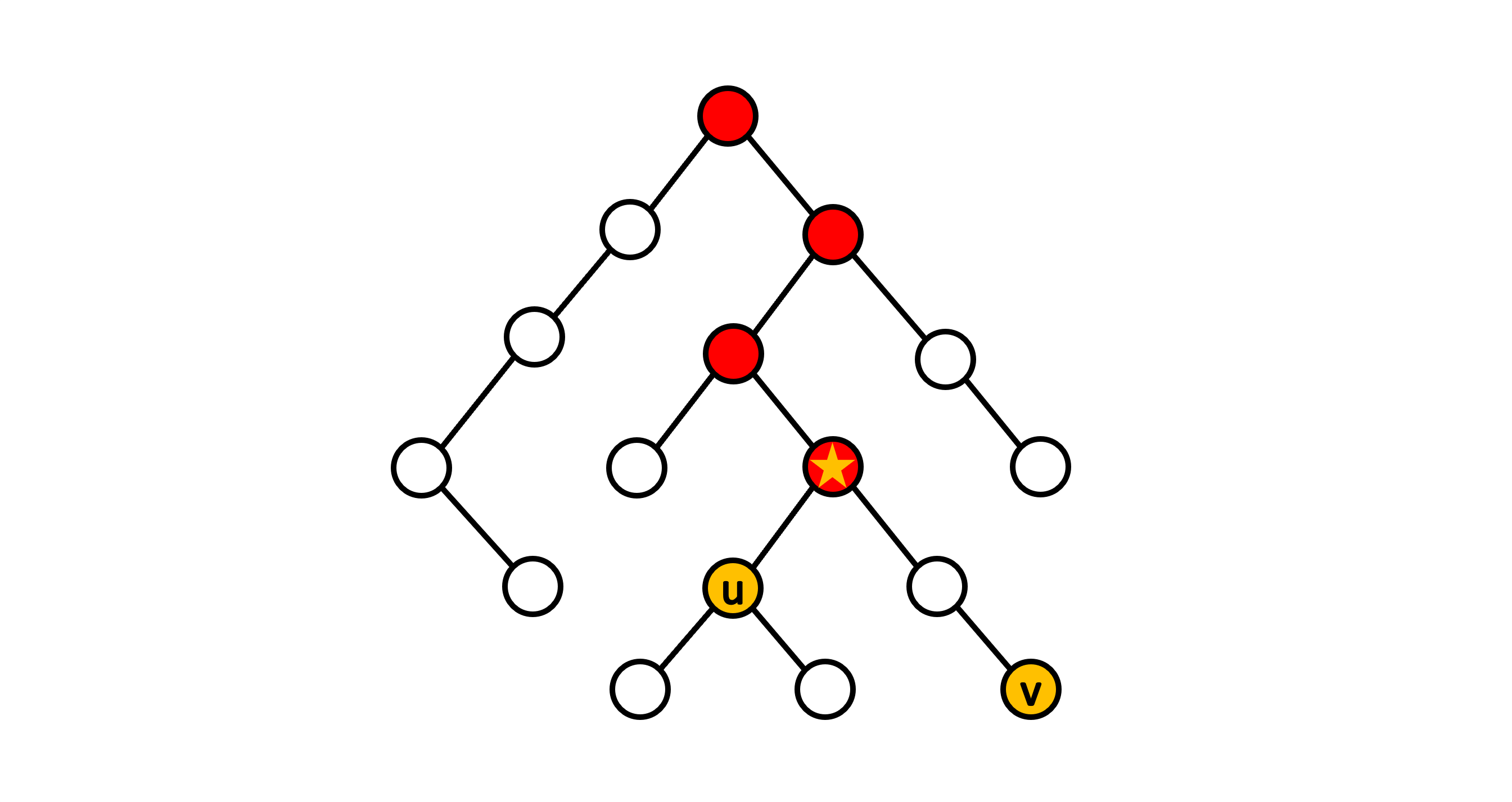
讀者們可以參考下圖,紅色的點為點 \( u \) 和點 \( v \) 的共同祖先,其中標星號的點為所有共同祖先中深度最深的點,也就是點 \( u \) 和點 \( v \) 的最近共同祖先。
相關性質
- 如果點 \( u \) 為點 \( v \) 的祖先,那麼 \( LCA(u,\ v) \) 為點 \( u \)。
- 如果點對 \( (u,\ v) \) 不具祖孫關係,那麼點 \( u \) 和點 \( v \) 會分別位於 \( LCA(u,\ v) \) 的兩個不同子樹內。
- \( LCA(u,\ v) \) 必定會位於點 \( u \) 到點 \( v \) 的最短路徑上(事實上路徑唯一)且為該路徑上深度最淺的點。
- 在 DFS 的走訪過程中,必定會先經過 \( LCA(u,\ v) \),接著再經過點 \( u \) 和點 \( v \)。
經典題型
給定一間擁有 \( N \) 名員工的公司且該公司具有樹狀層級制度。除了總經理以外,每名員工都配有一名上司,而你的任務是要處理以下形式的 \( Q \) 次詢問:
給定 \( a \) 和 \( b \),請輸出員工 \( a \) 和員工 \( b \) 的最近共同上司。
\( N,\ Q \leq 2 \times 10^5 \)
基本上此問題就是在問樹上兩點的最近共同祖先為何,下面我們將介紹幾種常見的作法。
演算法
Brute Force
一個直觀的做法是先從根開始作一次 DFS,確認出每個點的父節點以及時間戳(DFS 進行遞迴時進入該節點與離開該節點的時間戳記)。接著針對查詢點對 \( (u,\ v) \),我們每次將點 \( u \) 往上移動一位,直到點 \( u \) 是點 \( v \) 的祖先時,就找到最近共同祖先了。
而確認一個點是否為另一點的祖先,我們可以利用時間戳來判斷。假設點 \( u \) 為點 \( v \) 的祖先,在 DFS 遞迴的過程中必定會依序進入點 \( u \)、進入點 \( v \)、離開點 \( v \)、離開點 \( u \),由此我們可知進入點 \( u \) 的時間戳記必定會小於進入點 \( v \) 的時間戳記、離開點 \( v \) 的時間戳記必定會小於離開點 \( u \) 的時間戳記。透過此條件判斷,我們可以在 \( O(1) \) 的時間內得知兩點的祖孫關係。
總結一下此作法的時間複雜度:
-
預處理
- DFS 一次確認每個點的父節點以及時間戳:\( O(N) \)
-
單次查詢
- 對於查詢點對 \( (u,\ v) \),將點 \( u \) 持續往上移動一位直到點 \( u \) 為點 \( v \) 的祖先:\( O(N) \)
此作法需要花費 \( O(NQ) \) 的時間完成所有查詢。
Sample Code
- 用 adjacency list 來儲存樹的結構。
- 節點為 1-indexed 且根的父節點為 \( 0 \)。
tin[i]代表在 DFS 的過程中進入點 \( i \) 的時間。tout[i]代表在 DFS 的過程中離開點 \( i \) 的時間。par[i]代表第 \( i \) 個節點的父節點。- 在判斷兩點祖孫關係的
is_ancestor函數中,因為這邊我們定義了自己為自己的祖先,所以原先條件判斷中的<修正成了較寬鬆的<=。
#include <bits/stdc++.h>
using namespace std;
struct LCA {
int time = 0;
vector<int> par, tin, tout;
vector<vector<int>> adj;
void init(int n) {
par.assign(n + 1, 0);
tin.assign(n + 1, 0);
tout.assign(n + 1, 0);
adj.assign(n + 1, vector<int>());
}
void add_edge(int u, int v) {
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
void dfs(int u = 1, int p = 0) {
tin[u] = ++time;
par[u] = p;
for (int v : adj[u])
if (v != p) dfs(v, u);
tout[u] = ++time;
}
void build() {
dfs();
tout[0] = ++time;
}
bool is_ancestor(int u, int v) {
return tin[u] <= tin[v] && tout[v] <= tout[u];
}
int query(int u, int v) {
while (!is_ancestor(u, v)) u = par[u];
return u;
}
};
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int N, Q;
cin >> N >> Q;
LCA lca;
lca.init(N);
for (int i = 2; i <= N; ++i) {
int p;
cin >> p;
lca.add_edge(i, p);
}
lca.build();
for (int i = 0; i < Q; ++i) {
int u, v;
cin >> u >> v;
cout << lca.query(u, v) << "\n";
}
return 0;
}
直觀的做法通常很慢,可以觀察到在上述做法當中,我們是一個點一個點慢慢往上檢查,導致單次查詢的時間複雜度為線性。而我們接下來要介紹另外一種做法 Binary Lifting,中文稱作倍增法,即是針對這一點去做優化。
Binary Lifting
根據最近共同祖先的定義,我們可以觀察到在點 \( u \) 的祖先中找 \( LCA(u,\ v) \) 本身具有單調性,也就是說在往上檢查點 \( u \) 祖先的過程中,我們依序會先經過一連串的點不是點 \( v \) 的祖先,接著經過 \( LCA(u,\ v) \),最後經過一連串的點為點 \( v \) 的祖先。示意圖如下,紅色的點代表為點 \( u \) 的祖先但不為點 \( v \) 的祖先,綠色的點代表為點 \( u \) 和點 \( v \) 的共同祖先。
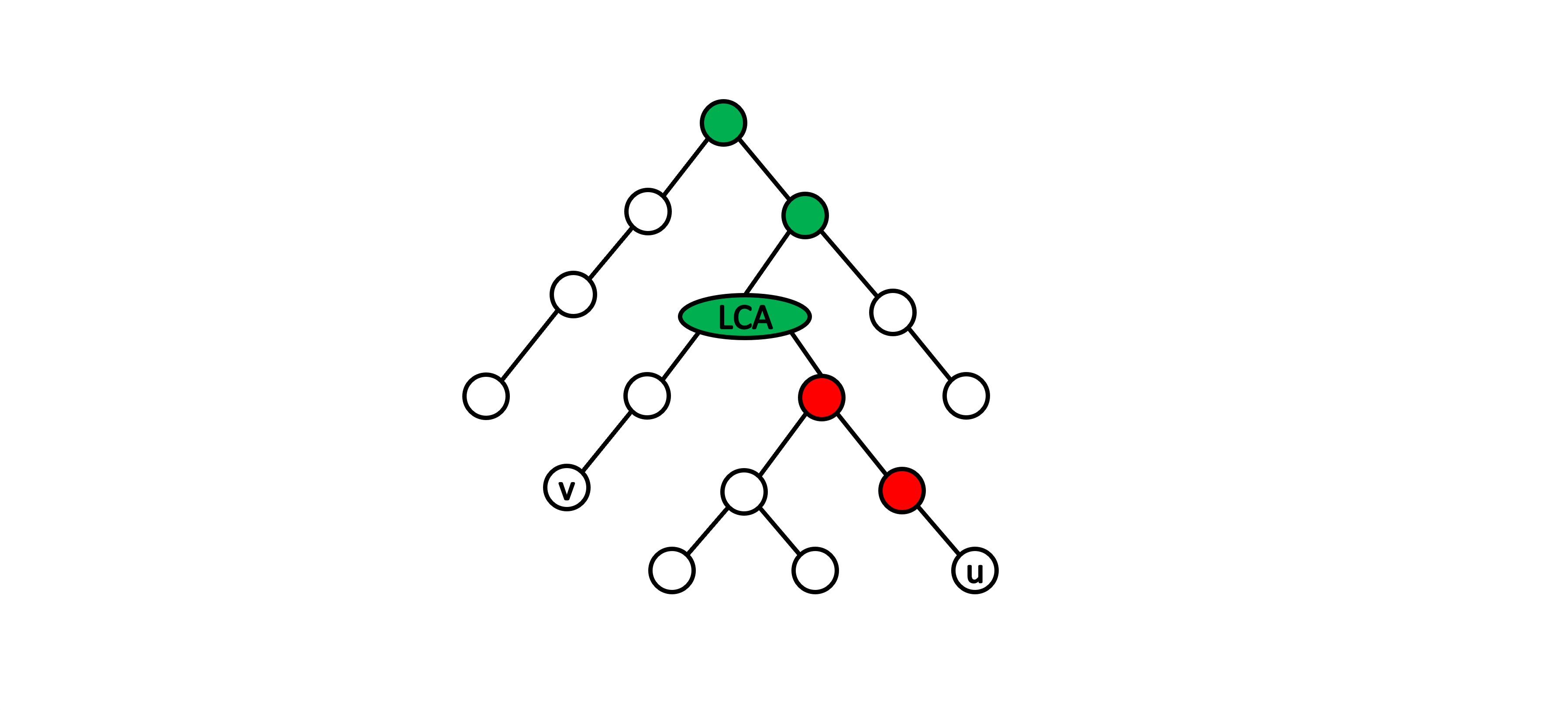
根據此單調性,我們可以利用二分搜來加速。而在二分搜的實作上,不同於傳統的二分搜有著明確的左界和右界,這邊我們從最大可能的 \( i \) 開始嘗試每次讓點 \( u \) 往上跳 \( 2^i \) 的距離 \( (0\leq i\leq\lfloor\log N\rfloor) \)。對於每次嘗試的 \( i \),如果點 \( u \) 的第 \( 2^i \) 個祖先不為點 \( v \) 的祖先,那麼我們就讓點 \( u \) 抬升至該點。反之,我們不做任何抬升。直到 \( i=0 \) 的嘗試結束後,我們就可以知道點 \( u \) 的父節點為最近共同祖先。
怎麼得出這個結論的呢?考慮特定的 \( i \),我們可以發現在嘗試完 \( i \) 之後,點 \( u \) 和 \( LCA(u,\ v) \) 的距離必定會小於等於 \( 2^i \)。因此等到 \( i=0 \) 的嘗試結束後,我們可以知道點 \( u \) 和 \( LCA(u,\ v) \) 的距離會小於等於 \( 1 \)。此外,因為我們在整個二分搜的過程中只會讓點 \( u \) 往上跳至不為點 \( v \) 祖先的點,所以我們也可以知道點 \( u \) 和 \( LCA(u,\ v) \) 的距離在二分搜的過程中必定會大於等於 \( 1 \) 且點 \( u \) 不會是點 \( v \) 的祖先。結合兩觀察可知,二分搜結束後點 \( u \) 和 \( LCA(u,\ v) \) 的距離會剛好等於 \( 1 \) 且點 \( u \) 不為點 \( v \) 的祖先。因此,點 \( u \) 的父節點即為 \( LCA(u,\ v) \)。
然而如果想要在 \( O(1) \) 的時間內檢查點 \( u \) 的第 \( 2^i \) 個祖先是否為點 \( v \) 的祖先,我們需要在預處理時多紀錄每個點的第 \( 2^i \) 個祖先的資訊 \( (0\leq i\leq\lfloor\log N\rfloor) \),實作上我們可以利用 Dynamic Programming 的概念。假設我們想知道點 \( u \) 的第 \( 2^i \) 個祖先是誰,我們可以將問題等同於點 \( u \) 的第 \( 2^{i-1} \) 個祖先的第 \( 2^{i-1} \) 個祖先是誰,聽起來有點饒口,不清楚的讀者可以看以下示意圖:
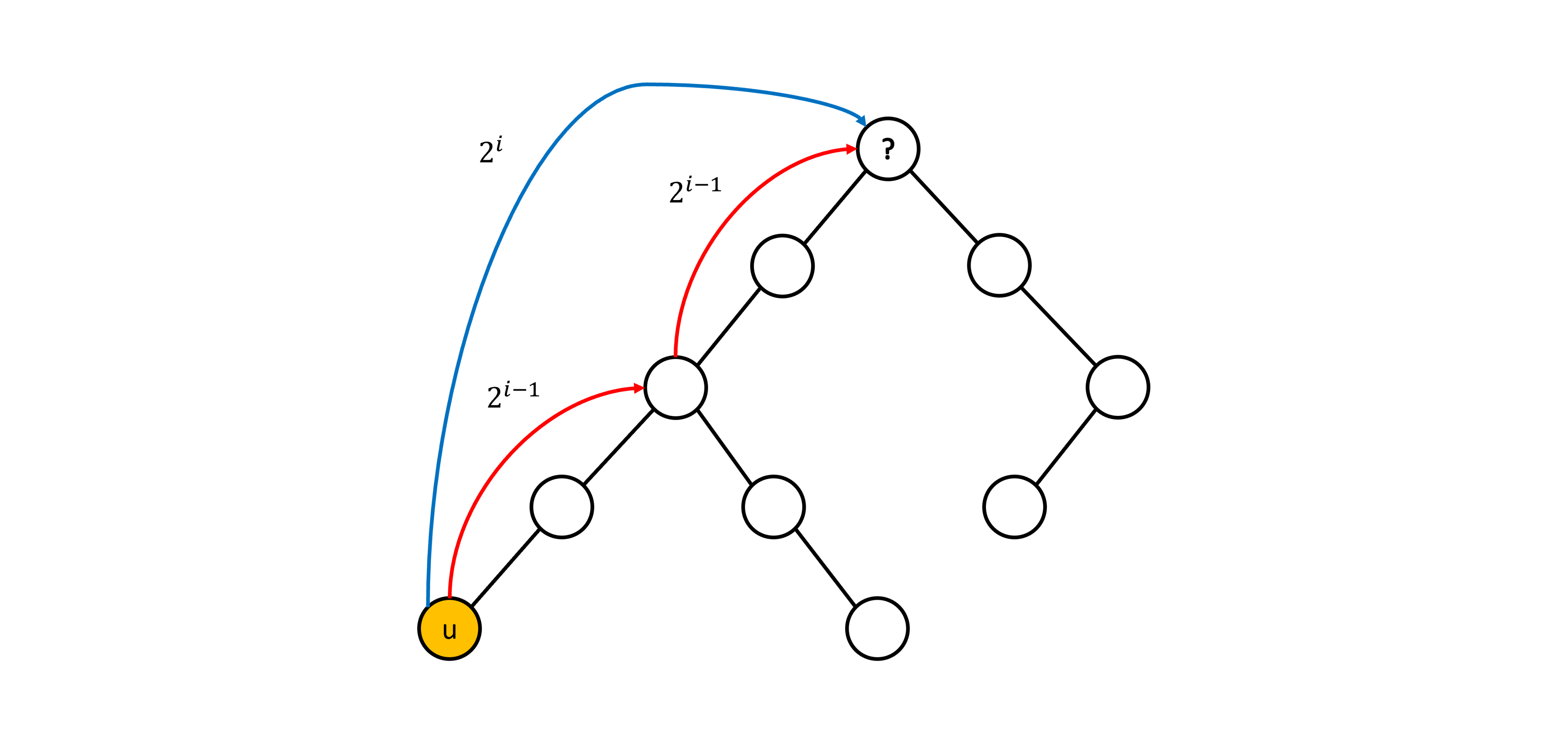
根據這個想法,我們可以列出下列遞迴關係式:
$$ancestor(u,\ i) = \begin{cases} parent(u) & \text {$i = 0$} \newline ancestor(ancestor(u,\ i-1),\ i-1) & \text{$i > 0$} \end{cases}$$
這邊 \( ancestor(u,\ i) \) 代表點 \( u \) 的第 \( 2^i \) 個祖先。
利用上述關係式,我們可以靠 bottom up 的填表方式在 \( O(N\log N) \) 時間內預處理完所有點的第 \( 2^i \) 個祖先的資訊。等到要進行二分搜的時候,我們就可以搭配時間戳在 \( O(1) \) 的時間內檢查點 \( u \) 的第 \( 2^i \) 個祖先是否為點 \( v \) 的祖先,進而讓整個二分搜可以在 \( O(\log N) \) 的時間內完成。
總結一下整個做法:
-
預處理
- DFS 一次確認每個點的父節點以及時間戳:\( O(N) \)
- 解 DP 找出所有點的第 \( 2^i \) 個祖先 \( (0\leq i\leq\lfloor\log N\rfloor) \):\( O(N\log N) \)
-
單次查詢
- 檢查點對 \( (u,\ v) \) 的祖孫關係:\( O(1) \)
- 二分搜找出 LCA(如果需要):\( O(\log N) \)
此作法可以在 \( O((N+Q)\log N) \) 的時間內完成所有查詢。
Sample Code
- 節點為 1-indexed 且根的所有祖先節點均為 \( 0 \)。
tin[i]代表在 DFS 的過程中進入點 \( i \) 的時間。tout[i]代表在 DFS 的過程中離開點 \( i \) 的時間anc[i][j]代表第 \( i \) 個節點的第 \( 2^j \) 個祖先。
#include <bits/stdc++.h>
using namespace std;
struct LCA {
int time = 0, logN;
vector<int> tin, tout;
vector<vector<int>> adj, anc;
void init(int n) {
logN = __lg(n);
anc.assign(n + 1, vector<int>(logN + 1, 0));
tin.assign(n + 1, 0);
tout.assign(n + 1, 0);
adj.assign(n + 1, vector<int>());
}
void add_edge(int u, int v) {
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
void dfs(int u = 1, int p = 0) {
tin[u] = ++time;
anc[u][0] = p;
for (int i = 1; i <= logN; ++i) anc[u][i] = anc[anc[u][i - 1]][i - 1];
for (int v : adj[u])
if (v != p) dfs(v, u);
tout[u] = ++time;
}
void build() {
dfs();
tout[0] = ++time;
}
bool is_ancestor(int u, int v) {
return tin[u] <= tin[v] && tout[v] <= tout[u];
}
int query(int u, int v) {
if (is_ancestor(u, v)) return u;
if (is_ancestor(v, u)) return v;
for (int i = logN; ~i; --i)
if (!is_ancestor(anc[u][i], v)) u = anc[u][i];
return anc[u][0];
}
};
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int N, Q;
cin >> N >> Q;
LCA lca;
lca.init(N);
for (int i = 2; i <= N; ++i) {
int p;
cin >> p;
lca.add_edge(i, p);
}
lca.build();
for (int i = 0; i < Q; ++i) {
int u, v;
cin >> u >> v;
cout << lca.query(u, v) << "\n";
}
return 0;
}
Tarjan's Offline Algorithm
Tarjan 提出的想法是利用 Disjoint Set 來動態地合併子樹,並且記錄集合中深度最淺的點,這邊我們稱為集合的最高點。一開始,所有點都位於一個獨立的並查集且集合的最高點為自己本身,共 \( N \) 個集合。接著利用 DFS 去走訪所有點,對於 DFS 走訪到的點 \( u \),我們依序進行以下的操作:
- DFS 遞迴下去搜索點 \( u \) 的所有子樹節點,遞迴過程中會將子樹節點的集合和點 \( u \) 所處的集合合併。
- 遞迴 return 後檢查所有包含點 \( u \) 在內的查詢點對,如果另一點為搜索過的狀態,那麼根據 Tarjan 的想法,此時我們可以知道該查詢點對的最近共同祖先為另一點所在集合的最高點。而如果另一點尚未被搜索過,代表說我們當前還沒有另一點的位置資訊,因此還不足以判斷兩點的最近共同祖先,直接跳過即可。
- 檢查完後將點 \( u \) 所處的集合和其父節點 \( p \) 所處的集合合併
- 將合併後集合的最高點設為點 \( p \)
Does Tarjan's idea work?
針對任意點對 \( (u,\ v) \) 的最近共同祖先,我們可以考慮以下兩種 Case。
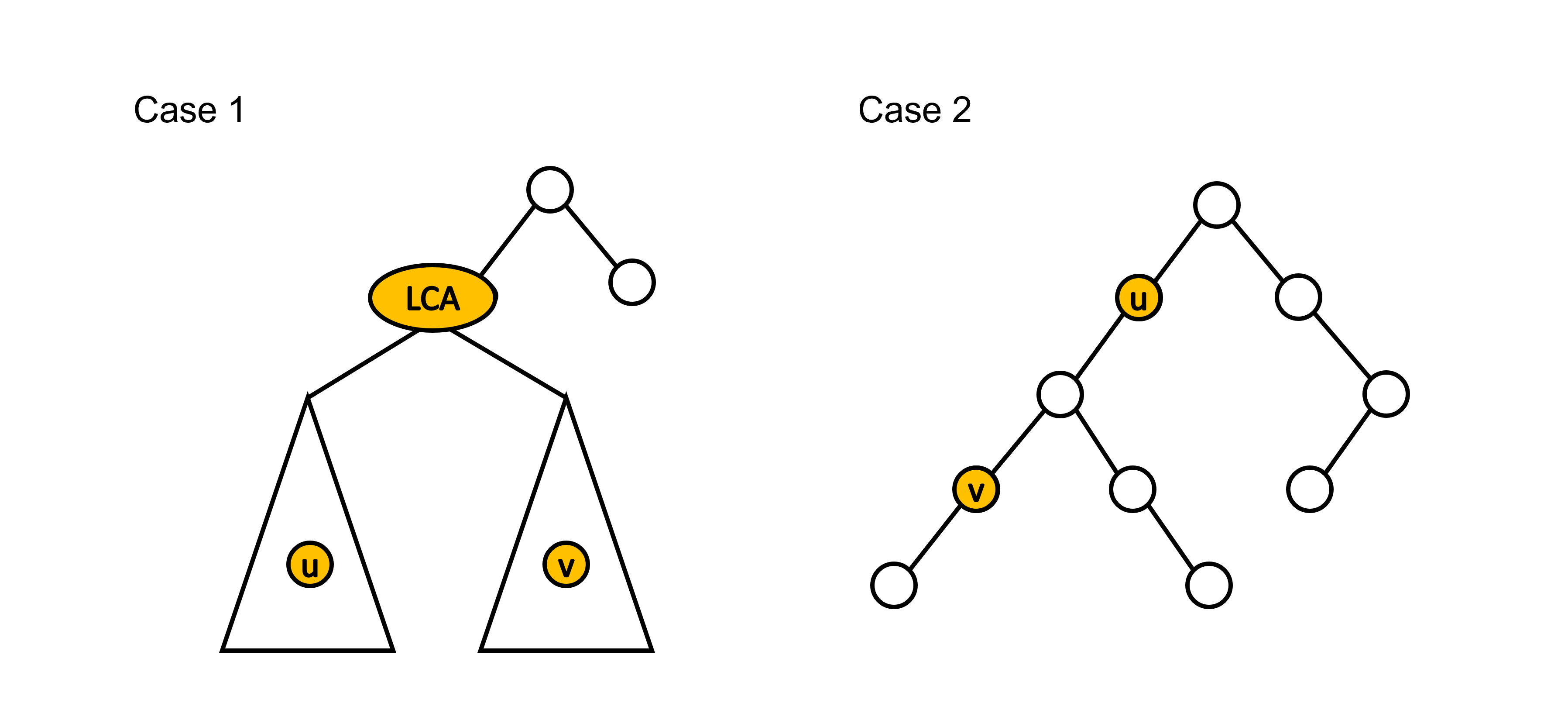
對於 Case 1,點 \( u \) 和點 \( v \) 不具祖孫關係,根據我們稍早提及的最近共同祖先的特性,可知點 \( u \) 和點 \( v \) 會分別位於 \( LCA(u,\ v) \) 的兩個不同子樹內。在 DFS 的走訪過程中,必定會先搜索 \( LCA(u,\ v) \),接著依序搜索點 \( u \)、返回 \( LCA(u,\ v) \)、搜索點 \( v \)(這邊不失一般性地假設會先搜索點 \( u \))。因此當點 \( v \) 遞迴搜索完其所有子樹節點時,點 \( u \) 會是搜索過的狀態。此時點 \( u \) 和 \( LCA(u,\ v) \) 會處於同一並查集且集合的最高點為 \( LCA(u,\ v) \)。
而對於 Case 2,點 \( u \) 和點 \( v \) 具有祖孫關係,點 \( u \) 為點對 \( (u,\ v) \) 的最近共同祖先。在 DFS 的走訪過程中,必定會先搜索點 \( u \),接著依序搜索點 \( v \)、返回點 \( u \)。因此當點 \( v \) 遞迴搜索完其所有子樹節點時,點 \( u \) 會是搜索過的狀態。此時點 \( u \) 所處並查集的最高點正好為點 \( u \),因為點 \( u \) 尚未搜索完其所有子樹節點,其所處的並查集尚未與其父節點所處的並查集合併,所以點 \( u \) 會是其所處並查集的最高點。
而當點 \( u \) 搜索完其所有子樹節點時,點 \( v \) 也會是搜索過的狀態。此時因為點 \( v \) 處於點 \( u \) 的子樹內,所以點 \( v \) 會和點 \( u \) 處於同一並查集且集合的最高點為點 \( u \)。
在以上兩種 Case 當中,可以發現對於任意查詢點對 \( (u,\ v) \),Tarjan 的想法都會是正確的。至於為什麼此演算法強制離線,因為 Tarjan 的想法是在 DFS 的走訪過程中去動態合併子樹。如果事先不知道查詢點對為何,我們就無法在走訪過程中去檢查點對之間的關係。
總結一下此作法的時間複雜度,以下所有 Disjoint Set 的操作都有用 union-by-rank 和 path compression 來優化:
- 初始化每個點的並查集和每個集合的最高點:\( O(N) \)
- DFS 走訪所有點:\( O(N) \)
- 每當一點 \( u \) 搜索完其所有子樹節點時,檢查所有包含點 \( u \) 在內的查詢點對,另一點是否為搜索過的狀態。如果已搜索過,則當前查詢點對的最近共同祖先為另一點所處並查集的最高點:\( O(Q\alpha(N)) \) --- 每個查詢點對只會被檢查兩次。
- 檢查完後將點 \( u \) 所處集合和其父節點 \( p \) 所處集合合併,並將合併集合的最高點設為點 \( p \):\( O(N\alpha(N)) \) --- 所有點的合併次數加起來至多 \( N \) 次。
因此針對離線的查詢,Tarjan's algorithm 可以有效率地在 \( O((N+Q)\alpha(N)) \) 的時間內完成,相當趨近於線性時間。
Sample Code
anc[i]代表有著節點 \( i \) 作為 representative 的集合的最高點。qry[i]存放所有滿足點對 \( (i,\ j) \) 為查詢點對的點 \( j \) 以及相對應是第幾個查詢點對。vis[i]代表點 \( i \) 是否被搜索過。ans[i]代表第 \( i \) 個查詢點對的最近共同祖先。
#include <bits/stdc++.h>
using namespace std;
struct DSU {
vector<int> par, size;
void init(int n) {
par.assign(n + 1, 0);
size.assign(n + 1, 1);
iota(par.begin(), par.end(), 0);
}
int find(int x) { return x == par[x] ? x : par[x] = find(par[x]); }
void unite(int u, int v) {
u = find(u), v = find(v);
if (size[u] > size[v]) swap(u, v);
par[u] = v;
size[v] += size[u];
}
};
struct LCA {
vector<vector<int>> adj;
vector<int> anc, ans;
vector<vector<pair<int, int>>> qry;
vector<bool> vis;
DSU dsu;
void init(int n, int q) {
adj.assign(n + 1, vector<int>());
anc.assign(n + 1, 0);
ans.assign(q, 0);
qry.assign(n + 1, vector<pair<int, int>>());
vis.assign(n + 1, false);
dsu.init(n);
}
void add_edge(int u, int v) {
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
void add_query(int u, int v, int idx) {
qry[u].emplace_back(v, idx);
qry[v].emplace_back(u, idx);
}
void dfs(int u = 1) {
vis[u] = 1;
anc[u] = u;
for (int v : adj[u]) {
if (vis[v]) continue;
dfs(v);
dsu.unite(u, v);
anc[dsu.find(u)] = u;
}
for (auto& q : qry[u]) {
int v = q.first, idx = q.second;
if (!vis[v]) continue;
ans[idx] = anc[dsu.find(v)];
}
}
void solve() { dfs(); }
int query(int idx) { return ans[idx]; }
};
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int N, Q;
cin >> N >> Q;
LCA lca;
lca.init(N, Q);
for (int i = 2; i <= N; ++i) {
int p;
cin >> p;
lca.add_edge(i, p);
}
for (int i = 0; i < Q; ++i) {
int u, v;
cin >> u >> v;
lca.add_query(u, v, i);
}
lca.solve();
for (int i = 0; i < Q; ++i) cout << lca.query(i) << "\n";
return 0;
}
Heavy Path Decomposition
此小節主要關注於如何利用樹鏈剖分的概念來查詢點對的最近共同祖先,如果讀者對於樹重鏈的定義以及其相關操作(跳輕邊)還不太清楚的話,建議可以先去觀看相關章節。
這邊我們簡單 recap 一下何謂重鏈,對於一點 \( u \) 的子節點 \( v \),如果以點 \( v \) 為根的子樹是所有點 \( u \) 子樹中 size 最大的,我們稱點 \( v \) 為重小孩,點 \( u \) 和點 \( v \) 相連的邊稱作重邊,由重邊相連所形成的路徑則稱作重鏈,示意圖如下(紅色路徑為重鏈):
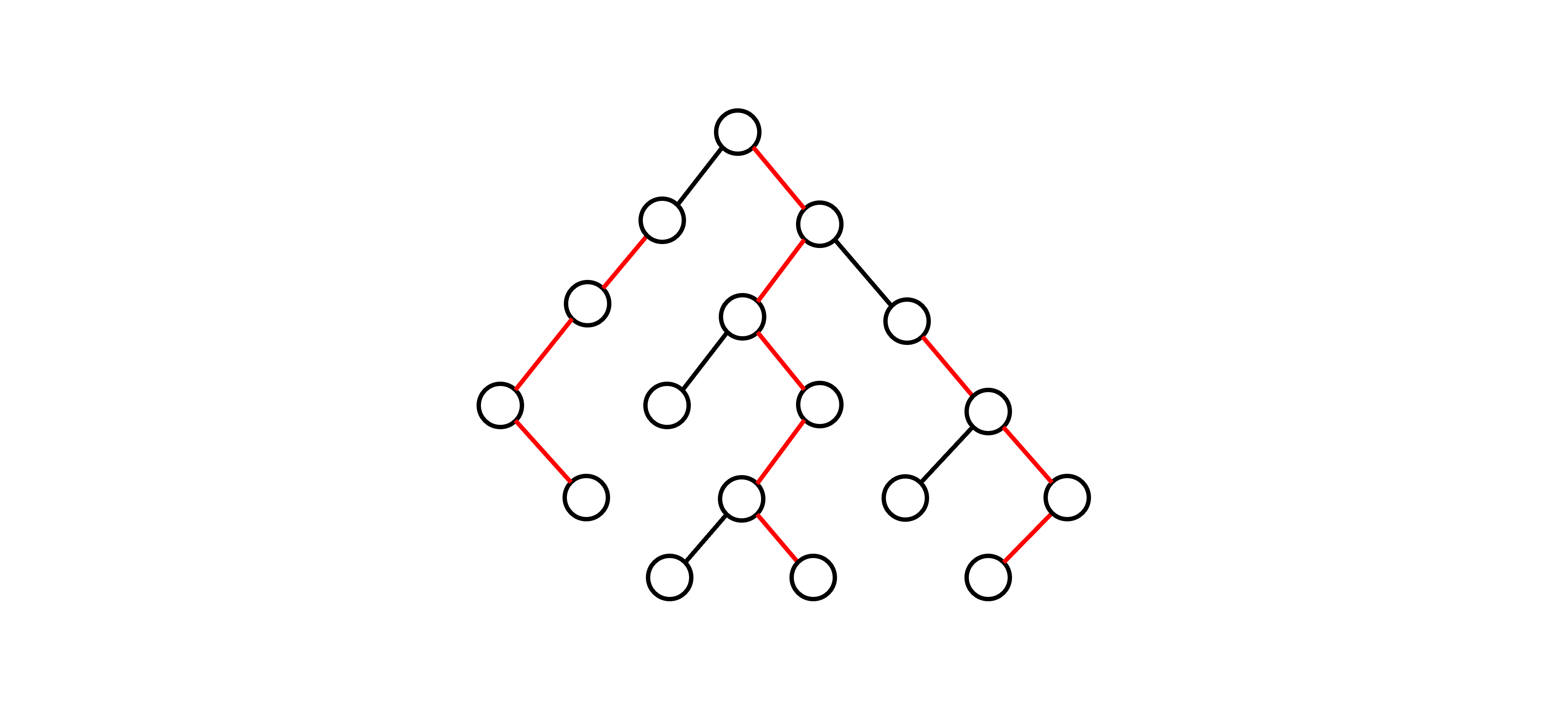
根據定義或是觀察上圖,我們可以知道處於同一重鏈上的任意兩點會具有祖孫關係。藉此特性,我們可以用來查詢任意點對的最近共同祖先。怎麼得出這個結論的呢?以下我們分成兩種 Case 來討論:
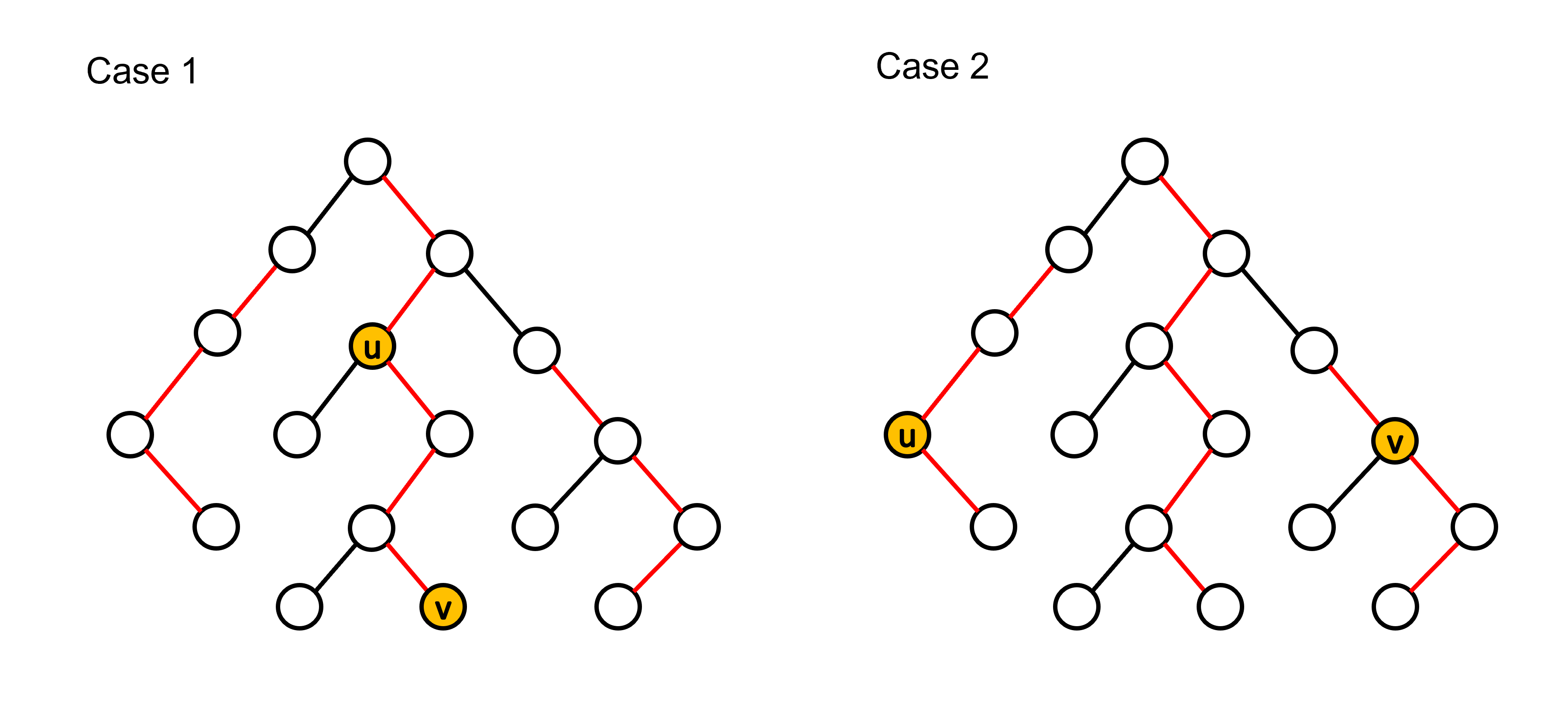
對於 Case 1,點 \( u \) 和點 \( v \) 位於同一重鏈上,兩點具有祖孫關係。因此我們可以知道點 \( u \) 為點對 \( (u,\ v) \) 的最近共同祖先。
而對於 Case 2,點 \( u \) 和點 \( v \) 位於不同重鏈上,我們可以透過跳輕邊的方式將點 \( u \) 和點 \( v \) 調整至同一條重鏈上。假設經過跳輕邊調整之後,點 \( u \) 和點 \( v \) 分別跳至點 \( i \) 和點 \( j \),我們可以得到以下資訊:
- 點 \( i \) 和點 \( j \) 為祖孫關係,因為位於同一條重鏈上。
- 點對 \( (i,\ u) \) 和點對 \( (j,\ v) \) 分別為祖孫關係。
沒有頭緒的讀者可以看以下示意圖:
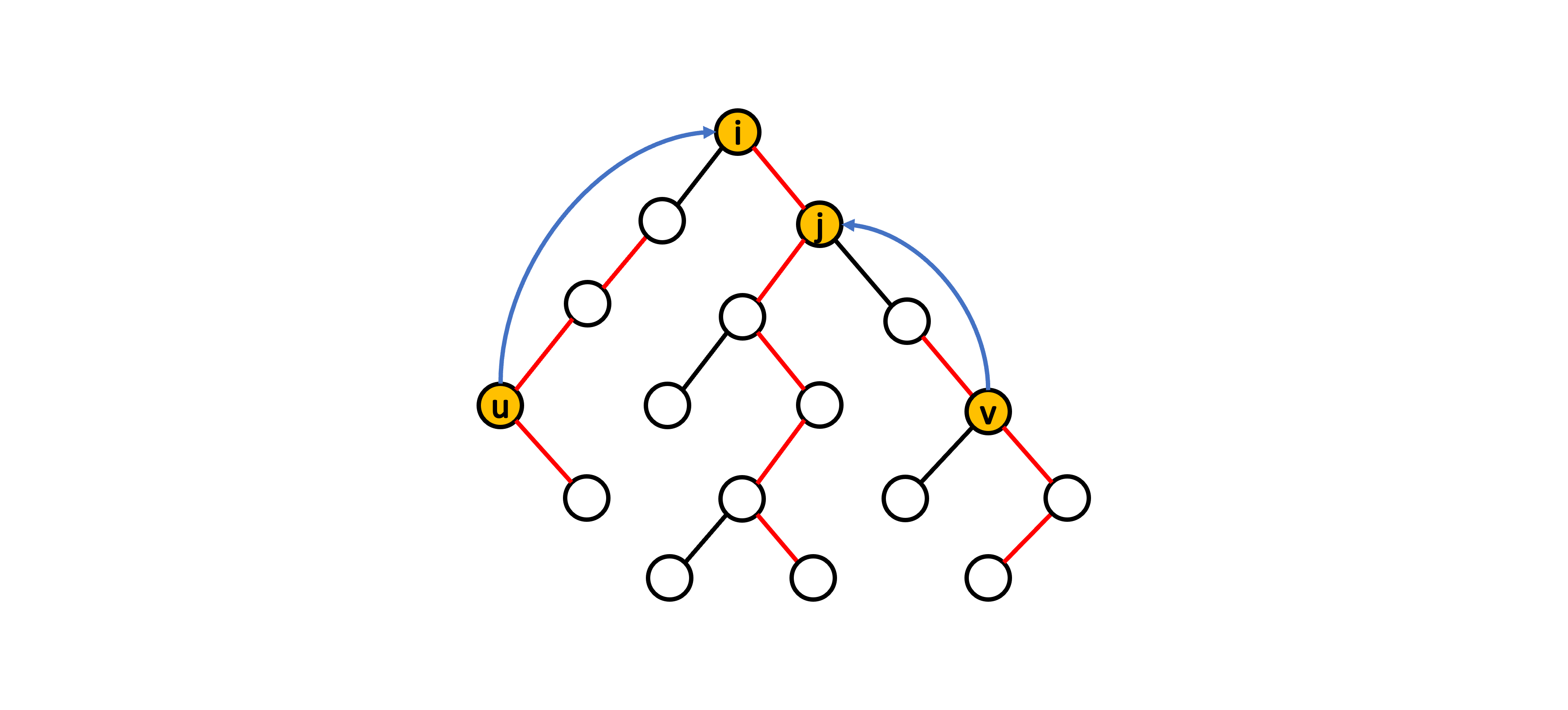
結合上述資訊可知,點 \( i \) 為點 \( u \) 和點 \( v \) 的共同祖先且點 \( u \) 和點 \( v \) 會在點 \( i \) 的不同子樹內,否則點 \( u \) 和點 \( v \) 在跳上來當前重鏈之前就會在同一重鏈上。因此對於 Case 2,可知點 \( i \) 會是點對 \( (u,\ v) \) 的最近共同祖先。
總結以下此作法的概念以及時間複雜度:
-
預處理
- 對樹作重鏈剖分,確認每個點所在的重鏈(一次 DFS 可完成):\( O(N) \)
- DFS 的過程中同時記錄點深度、父節點、重鏈上深度較淺的點:\( O(N) \)
-
單次查詢
- 透過不斷跳輕邊將查詢點對 \( (u,\ v) \) 調整至同一重鏈上:\( O(\log N) \)
- 深度較淺的點即為點對的最近共同祖先
此作法可以在 \( O(N+Q\log N) \) 的時間內完成所有查詢。
Sample Code
depth[i]代表第 \( i \) 個節點的深度。heavyChild[i]代表第 \( i \) 個節點的重小孩。size[i]代表以第 \( i \) 個節點為根的子樹大小。top[i]代表點 \( i \) 所處重鏈上深度最淺的點。par[i]代表第 \( i \) 個節點的父節點。
#include <bits/stdc++.h>
using namespace std;
struct LCA {
vector<int> depth, heavyChild, size, top, par;
vector<vector<int>> adj;
void init(int n) {
depth.assign(n + 1, 0);
heavyChild.assign(n + 1, -1);
size.assign(n + 1, 1);
top.assign(n + 1, 0);
par.assign(n + 1, 0);
adj.assign(n + 1, vector<int>());
}
void add_edge(int u, int v) {
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
void findHeavyChild(int u = 1, int p = 0) {
par[u] = p;
for (int v : adj[u]) {
if (v == p) continue;
depth[v] = depth[u] + 1;
findHeavyChild(v, u);
size[u] += size[v];
if (heavyChild[u] == -1 || size[heavyChild[u]] < size[v])
heavyChild[u] = v;
}
}
void build_link(int u = 1, int p = 0, int link_top = 1) {
top[u] = link_top;
if (heavyChild[u] == -1) return;
build_link(heavyChild[u], u, link_top);
for (int v : adj[u]) {
if (v == p || v == heavyChild[u]) continue;
build_link(v, u, v);
}
}
void build() {
findHeavyChild();
build_link();
}
int query(int u, int v) {
int tu = top[u], tv = top[v];
while (tu != tv) {
if (depth[tu] > depth[tv]) {
u = par[tu];
tu = top[u];
} else {
v = par[tv];
tv = top[v];
}
}
return depth[u] < depth[v] ? u : v;
}
};
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int N, Q;
cin >> N >> Q;
LCA lca;
lca.init(N);
for (int i = 2; i <= N; ++i) {
int p;
cin >> p;
lca.add_edge(i, p);
}
lca.build();
for (int i = 0; i < Q; ++i) {
int u, v;
cin >> u >> v;
cout << lca.query(u, v) << "\n";
}
return 0;
}
轉化成 RMQ 問題
有許多問題可以透過轉化成其他問題的方式來獲得很好的解法,LCA 問題也不是例外。我們可以透過歐拉路徑在線性時間內將 LCA 問題轉化成另一經典問題(Range Minimum Query),解決 RMQ 問題的同時也就解決了 LCA 問題。
歐拉路徑
Eulerian path,中文譯作尤拉路徑或是歐拉路徑。在圖論中,我們定義歐拉路徑為圖中滿足剛好經過每一條邊各一次的路徑,而如果同時要求路徑起點和終點必須相同的話,該路徑我們也稱作 Eulerian circuit,中文譯作尤拉或歐拉迴路。然而,並不是所有圖我們都可以在上面找到歐拉路徑或是歐拉迴路,圖必須符合下列條件:
-
無向圖:如果恰有兩點的度數為奇數,則存在歐拉路徑,此二點分別為起終點。如果全部的點度數都是偶數,則存在歐拉迴路。
-
有向圖:如果恰有一點的出度等於入度 + 1、另有一點的入度等於出度 + 1,其餘皆入度等於出度,則存在歐拉路徑,此二點分別為起終點。如果全部的點入度等於出度,則存在歐拉迴路。
而在此小節中,我們主要關心樹上是否存在歐拉路徑,所以我們針對樹來討論。在樹上,我們可以把樹邊想成是一去一回的兩條有向邊,可以發現樹會滿足有向圖中歐拉迴路的條件,代表說我們必定可以在樹上找到歐拉路徑。
確認樹上必有歐拉路徑之後,我們接著馬上來看看如何利用歐拉路徑將 LCA 問題轉化成 RMQ 問題。
建立歐拉路徑
我們可以利用 DFS 走訪來建立歐拉路徑,通常會用一陣列來儲存。在 DFS 的走訪過程中,每經過一個點我們就把該點加入到歐拉路徑,包含返回時所經過的點,不是很清楚的讀者可以看以下示意圖:
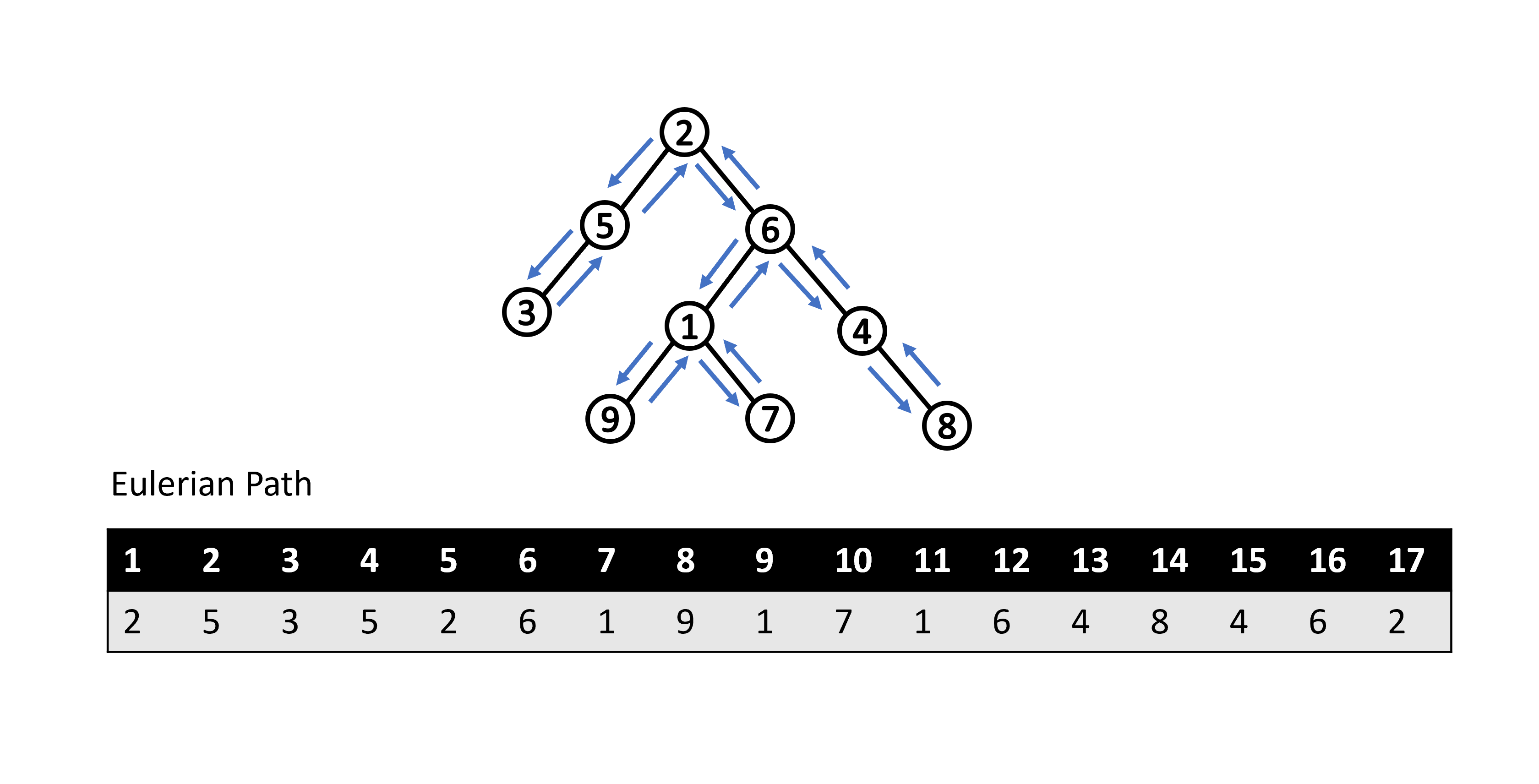
觀察歐拉路徑我們可以發現,假設我們想知道點對 \( (u,\ v) \) 的最近共同祖先是誰,我們只需要沿著歐拉路徑從點 \( u \) 到點 \( v \) 找路徑上深度最淺的點就會是點對 \( (u,\ v) \) 的 LCA,其中點 \( u \) 和點 \( v \) 在歐拉路徑上可能會出現很多次,我們取第一次出現即可。比如說如下圖所示,點對 \( (1,\ 8) \) 的最近共同祖先就會是沿著歐拉路徑從第一次出現的點 \( 1 \) 到第一次出現的點 \( 8 \),路徑上所經過深度最淺的點,也就是點 \( 6 \)。
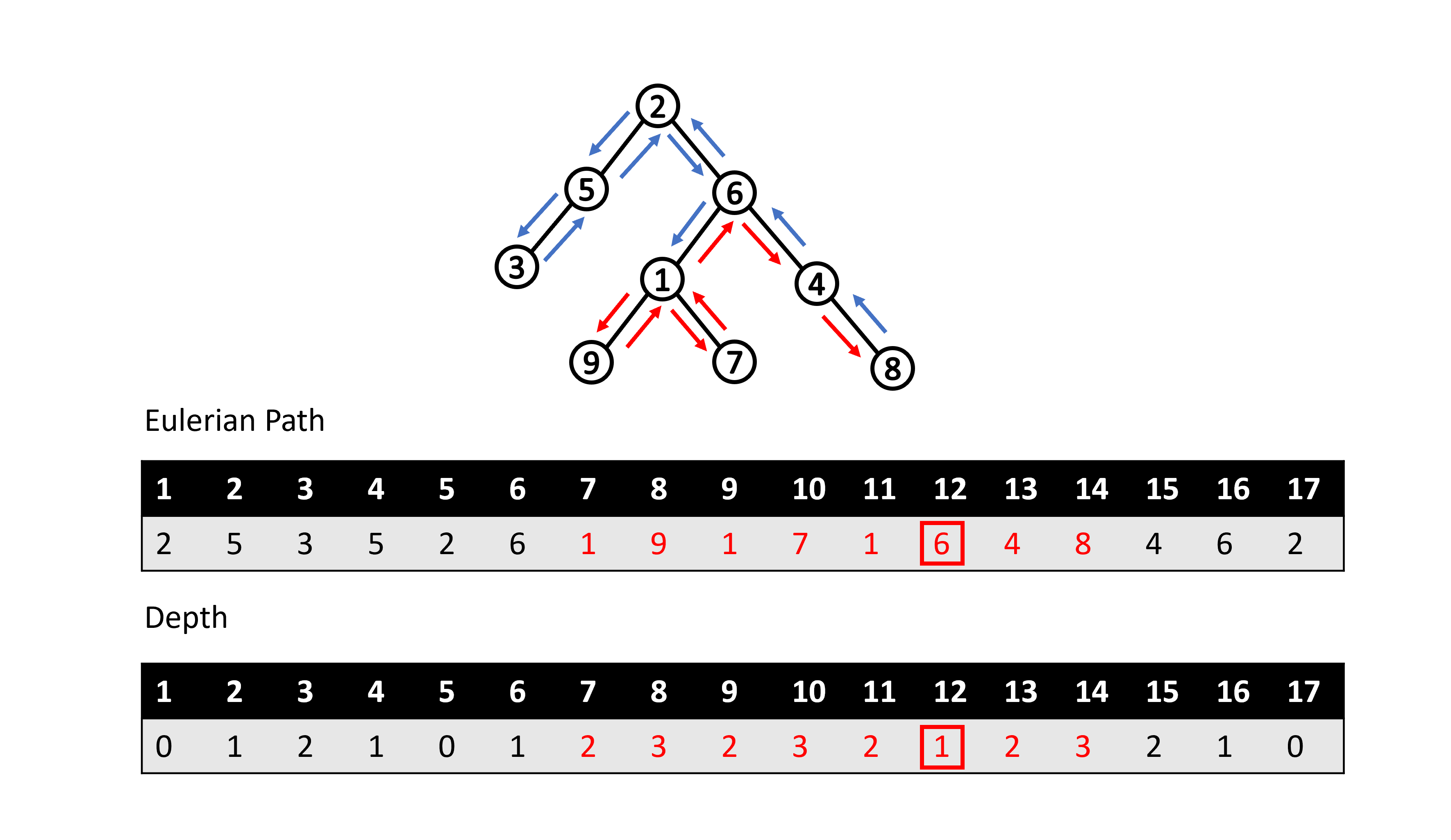
怎麼得出這個結論的呢?我們可以發現在歐拉路徑上從點 \( u \) 到點 \( v \) 的任意一條路徑,必定會包含點 \( u \) 到點 \( v \) 的最短路徑。根據稍早提及的最近共同祖先的特性,我們可以知道 \( LCA(u,\ v) \) 會位於最短路徑上且為該路徑上深度最淺的點。而除了經過最短路徑之外,我們可能會多經過有在最短路徑上的點的子樹,但由於多經過的這些點深度都比 \( LCA(u,\ v) \) 深。因此針對從點 \( u \) 到點 \( v \) 的任意一條路徑,\( LCA(u,\ v) \) 都會是路徑上深度最淺的點,所以在查詢時我們可以選擇任意一條路徑。但為了方便起見,我們可以在不影響結果的情況下針對所有查詢都選擇從第一次出現的點 \( u \) 到第一次出現點 \( v \) 的路徑。
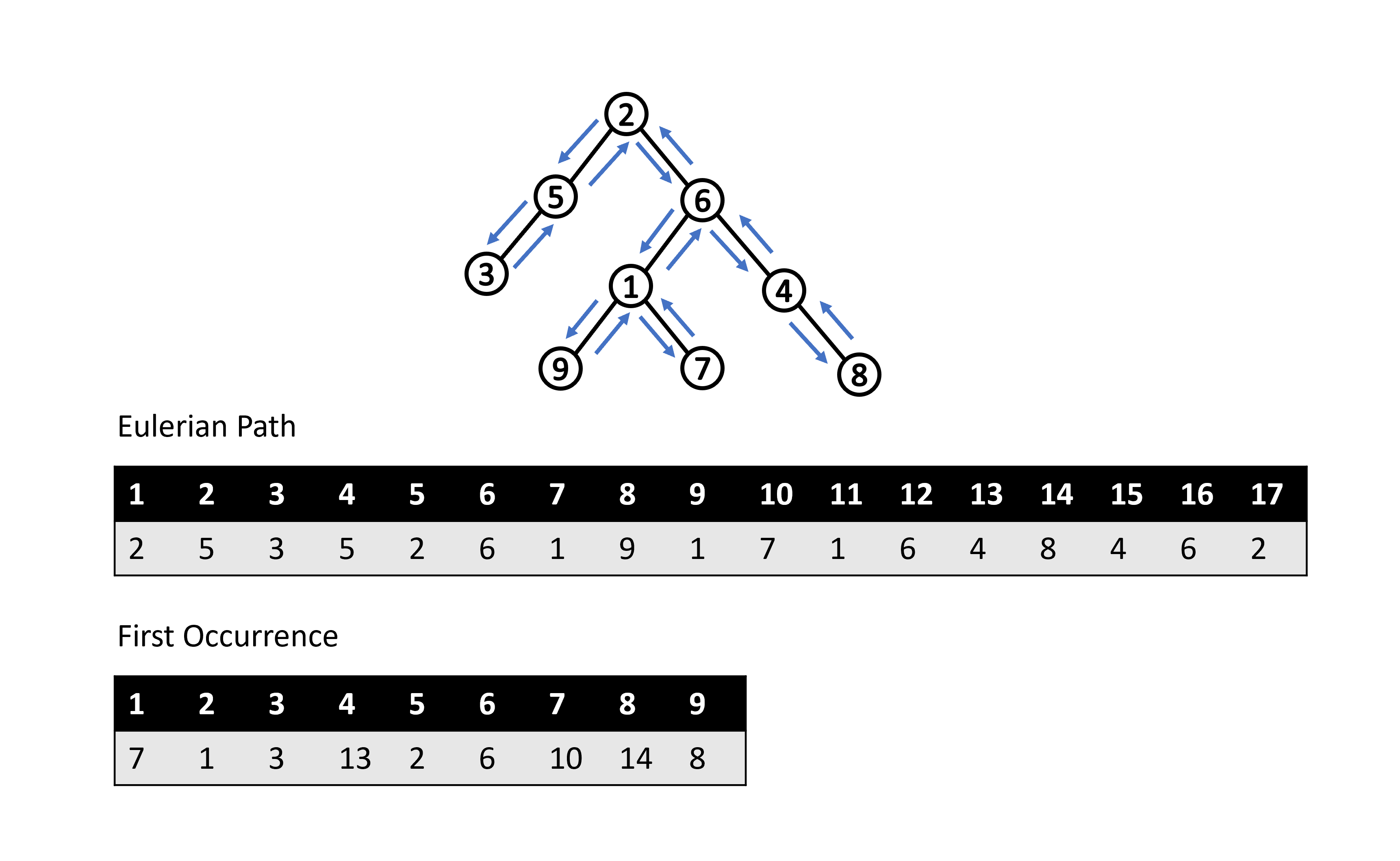
因此,透過歐拉路徑我們可以將 LCA 問題轉化成找區間最小值的問題。一般來說,我們會另開一陣列來記錄每個點在歐拉路徑上第一次出現時所對應的 index,方便我們在 \( O(1) \) 時間內找到對應的區間。
有了上述預處理好的陣列後,剩下的工作就會是處理 RMQ 問題。對於 RMQ 問題,有許多經典的解法像是線段樹、序列分塊或是 Sparse Table,這邊我們不會細講這些經典解法的概念和實作細節,有興趣的讀者可以去觀看相關的章節。而此小節我們主要關注於如何利用對歐拉路徑的陣列分塊來達到 \( O(N) \) 預處理、每次查詢 \( O(1) \) 的做法。
O(n) - O(1) LCA
觀察歐拉路徑陣列每個元素的深度我們可以發現,陣列中相鄰的值會剛好差 1。原因是因為在建立歐拉路徑時,我們每次只會往上或是往下走一步,所以在歐拉路徑陣列中相鄰的點,點深度會剛好差 1。基於此特性,我們可以用來優化區間最小值的查詢。
高度分塊的 RMQ 同樣是基於序列分塊的概念,先將 Depth 陣列分成 \( \frac{N}{K} \) 個大小為 \( K \) 的塊,每一塊維護該塊最小值所對應到的 index,存放在另開的 Block 陣列中,如下圖所示(範例中 \( K = 2 \))。
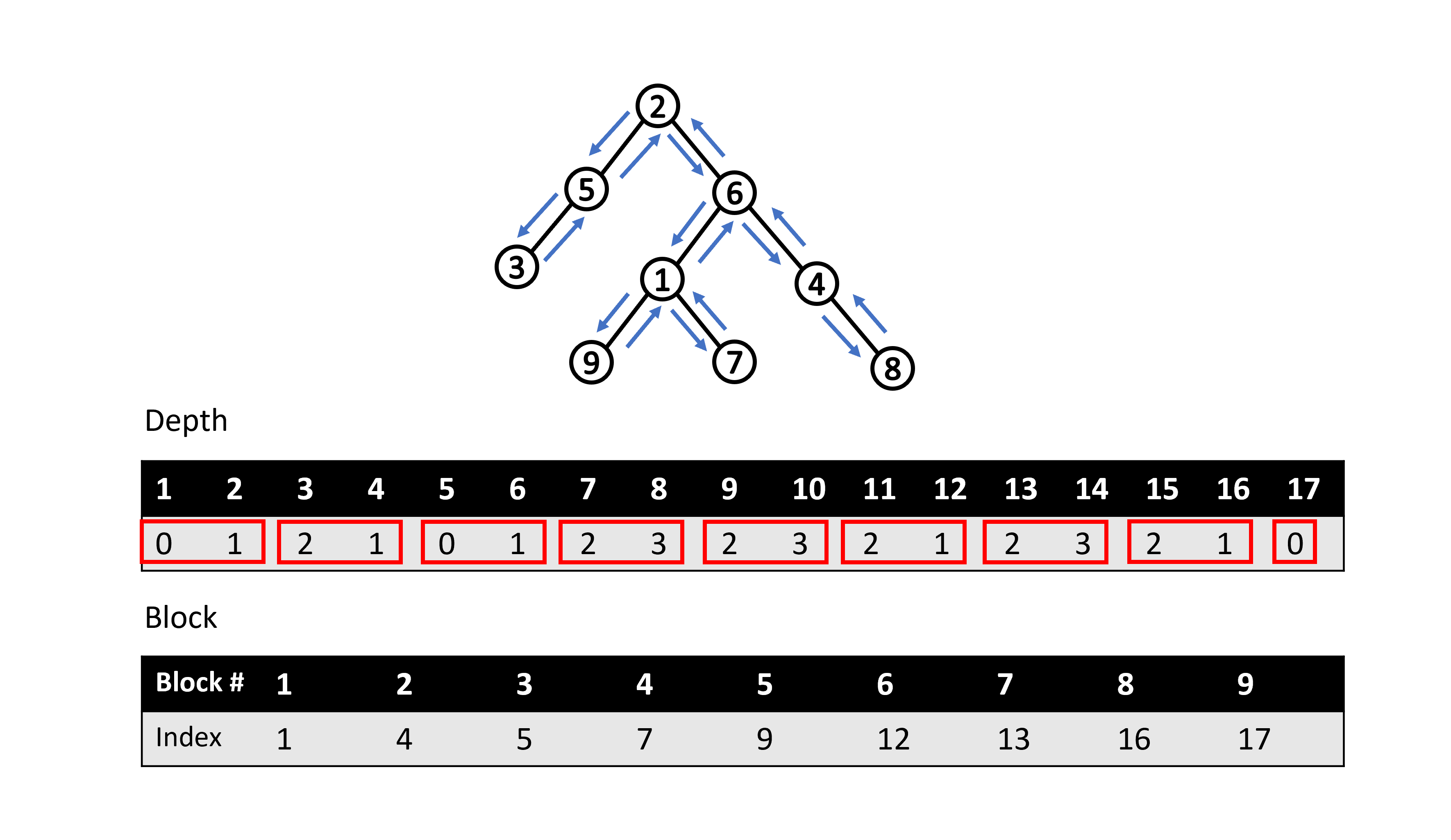
利用分塊查詢的概念,我們會需要進行塊內以及塊之間的最小值搜索。假設我們想知道 Depth 陣列上區間 \( \left[l,\ r \right] \) 的最小值,我們可以分成兩種 Case 來討論。如果 \( l \) 和 \( r \) 屬於同一塊 block,那麼我們只要在該塊裡面從 \( l \) 到 \( r \) 暴力搜索最小值就好。但如果 \( l \) 和 \( r \) 屬於不同塊,我們就需要知道區間 \( \left[l,\ l^{\prime} \right] \) 的最小值、區間 \( \left[r^{\prime},\ r \right] \) 的最小值、\( l \) 和 \( r \) 中間橫跨過的所有塊的最小值,三個再取最小值即為區間 \( \left[l,\ r \right] \) 的最小值。這邊 \( l^{\prime} \) 為 \( l \) 所屬塊的最後一個 index,\( r^{\prime} \) 則為 \( r \) 所屬塊的第一個 index。
對於搜索塊之間的最小值,相較於直接遍歷過 \( l \) 和 \( r \) 中間所有塊,我們可以在 \(O\left(\frac{N}{K}\log\frac{N}{K}\right) \) 的時間內先對 Block 陣列建 Sparse Table。基於 RMQ 的特性,之後的查詢可以在 \( O(1) \) 時間內辦到。而對於在塊內搜索最小值,暴力做的話會需要 \( O(K) \) 的時間,有沒有更快的作法?
還記得在此小節一開始我們提及的歐拉路徑的特性嗎?藉由該特性,我們其實可以透過像是建立差分數組的方式來將每一塊 block 轉換成大小為 \( K-1 \) 的塊,使得新塊內元素只會有 \( +1 \) 和 \( -1 \) 兩種可能性。舉例來說,假設存在一塊 block A 其內容為 \( \left[0,1,2,1,0\right] \),我們可以將其轉換成內容為 \( \left[1,1,-1,-1\right] \) 的新塊。而一般來說我們會將 \( -1 \) 轉成 \( 0 \),用 bitmask 的方式來方便紀錄以及識別每一種新塊。
透過此轉換,我們可以發現新塊最多只會有 \( 2^{K-1} \) 種。而轉換後有著相同 bitmask 的塊,塊內所有區間組合的最小值在塊內所對應的 index offset 都會是相同的,因為新塊內容其實間接說明了原塊內的深度分布。舉例來說,假設存在一塊 block A 其內容為 \( \left[0,1,2\right] \),一塊 block B 其內容為 \( \left[2,3,4\right] \)。在經過轉換之後,這兩塊會對應到相同的 bitmask,而我們可以發現
對於 block A 的所有區間組合:
- 區間 \( [1,\ 1] \)、\( [2,\ 2] \) 和 \( [3,\ 3] \) 的最小值分別是塊內第 \( 1 \) 個、第 \( 2 \) 個和第 \( 3 \) 個元素
- 區間 \( [1,\ 2] \) 的最小值為 \( min(0,\ 1) \),也就是 \( 0 \),同時對應到塊內的第 \( 1 \) 個元素
- 區間 \( [2,\ 3] \) 的最小值為 \( min(1,\ 2) \),也就是 \( 1 \),同時對應到塊內的第 \( 2 \) 個元素
- 區間 \( [1,\ 3] \) 的最小值為 \( min(0,\ 1,\ 2) \),也就是 \( 0 \),同時對應到塊內的第 \( 1 \) 個元素
而對於 block B 的所有區間組合:
- 區間 \( [1,\ 1] \)、\( [2,\ 2] \) 和 \( [3,\ 3] \) 的最小值分別是塊內第 \( 1 \) 個、第 \( 2 \) 個和第 \( 3 \) 個元素
- 區間 \( [1,\ 2] \) 的最小值為 \( min(2,\ 3) \),也就是 \( 2 \),同時對應到塊內的第 \( 1 \) 個元素
- 區間 \( [2,\ 3] \) 的最小值為 \( min(3,\ 4) \),也就是 \( 3 \),同時對應到塊內的第 \( 2 \) 個元素
- 區間 \( [1,\ 3] \) 的最小值為 \( min(2,\ 3,\ 4) \),也就是 \( 2 \),同時對應到塊內的第 \( 1 \) 個元素
觀察一下可以發現,這兩塊內所有區間組合的最小值在個別塊內所對應的 index offset 相同。因此,相較於每次查詢時都去暴力搜索塊內的最小值,我們其實可以預處理每一種新塊內所有區間組合的最小值在塊內所對應的 index offset,這部分會花費 \( O(2^{K-1}K^2) \) 的時間。但針對之後塊內區間搜索最小值的查詢,我們就可以在 \( O(1) \) 的時間內用塊的 bitmask 查表得知。
而一般為了比較好的時間複雜度,\( K \) 我們會取 \( 0.5\log N \),這樣預處理塊內區間最小值的時間複雜度即為
$$ O(2^{K-1}K^2) = O\left( 2^{0.5\log N}\log^2N\right) = O(\sqrt{N}\log^2N) = O(N) $$
而對 Block 陣列建 Sparse Table 的時間複雜度則為
$$ \begin{aligned} O\left(\frac{N}{K}\log\frac{N}{K}\right) &= O\left( \frac{2N}{\log N}\log\frac{2N}{\log N}\right) = O\left[ \frac{2N}{\log N}\left(1+\log\frac{N}{\log N}\right)\right] \newline &= O\left( \frac{2N}{\log N}+2N-\frac{2N\log\log N}{\log N}\right) = O(N) \newline \end{aligned} $$
兩項預處理的時間複雜度均被壓到 \( O(N) \),這同時也是理論上最佳的時間複雜度。然而讀者可能會有個疑問:\( K \) 為甚麼不取 \( \log N \) 就好,還需要除以 \( 2 \)。為了回答這個疑問,這邊我們簡單將 \( K = \log N \) 代入兩項預處理的時間複雜度,可以發現對 Block 陣列建 Sparse Table 的時間複雜度仍為 \( O(N) \),但預處理塊內區間最小值的時間複雜度會變成
$$ O(2^{K-1}K^2) = O\left( 2^{\log N}\log^2N\right) = O(N\log^2N) = \omega (N) $$
因此,整體預處理的時間複雜度會變成 \( O(N\log^2N) \),而不是理論最佳的 \( O(N) \)。
總結一下此作法跟整體時間複雜度:
-
預處理
-
DFS 一次建立歐拉路徑,同時記錄 Depth 和 First Occurrence 陣列:\( O(N) \)。
-
將 Depth 陣列分塊,每一塊維護最小值所對應的 index 並存放在 Block 陣列。與此同時,計算每一塊的 bitmask 並存放在另開的 Mask 陣列裡:\( O(N) \)。
-
對 Block 陣列建 Sparse Table:\(O\left(\frac{N}{K}\log\frac{N}{K}\right) \xrightarrow{K=0.5\log N} O(N) \)
-
對於 Mask 陣列裡每一塊的 bitmask,紀錄該塊所有區間組合的最小值在塊內所對應的 index offset:\( O(2^{K-1}K^2) \xrightarrow{K=0.5\log N} O(\sqrt{N}\log^2N) = O(N) \)
-
-
單次查詢
-
對於查詢點對 \( (u,\ v) \),從 First Occurrence 陣列得知相對應的查詢區間 \( \left[l,\ r \right] \):\( O(1) \)。
-
如果 \( l \) 和 \( r \) 屬於同一塊 block,先透過 Mask 陣列得知該塊的 bitmask 再去查表:\( O(1) \)。
-
如果 \( l \) 和 \( r \) 屬於不同塊,先透過 Mask 陣列得知 \( l \) 和 \( r \) 所屬塊的 bitmask,再去查表得知區間 \( \left[l,\ l^{\prime} \right] \) 的最小值、區間 \( \left[r^{\prime},\ r \right] \) 的最小值。而對於 \( l \) 和 \( r \) 中間所有塊的最小值,直接查 Block 陣列的 Sparse Table 就可以知道,最後這三個再取最小值即為區間 \( \left[l,\ r \right] \) 的最小值:\( O(1) \)。
-
上面兩種 Case 最後紀錄的都會是最小值所對應到的 index,有了 index 我們就可以利用歐拉路徑陣列得知點對 \( (u,\ v) \) 的最近共同祖先:\( O(1) \)。
-
因此,\( O(N) \) - \( O(1) \) LCA 可以讓我們在 \( O(N+Q) \) 的時間內完成所有查詢。
Sample Code
euler_path[i]代表歐拉路徑上的第 \( i \) 個點。depth[i]代表歐拉路徑上第 \( i \) 個點對應的點深度。first_vis[i]代表點 \( i \) 在 Eulerian path 上第一次出現時所對應的 index。block[i]記錄了第 \( i \) 個塊內最小值所對應的 index。mask[i]代表第 \( i \) 個塊的 bitmask。st[i][j]記錄了 block 陣列上區間 \( \left[i,\ i+2^j-1 \right] \) 中間所有塊的最小值所對應的 index。in_block_RMQ[i][j][k]記錄了 bitmask 為 \( i \) 的塊,區間 \( \left[j,\ k \right] \) 的最小值在塊內所對應的 index offset。- 以下範例程式碼較為繁複,建議讀者可以花點時間 trace 過一遍。
#include <bits/stdc++.h>
using namespace std;
struct LCA {
int M, block_size, block_cnt, table_size, ways;
vector<vector<vector<int>>> in_block_RMQ;
vector<vector<int>> adj, st;
vector<int> euler_path, depth, first_vis, lg, block, mask;
void init(int n) {
first_vis.assign(n + 1, 0);
adj.assign(n + 1, vector<int>());
}
void add_edge(int u, int v) {
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
void dfs(int u = 1, int p = 0, int d = 0) {
first_vis[u] = euler_path.size();
euler_path.emplace_back(u);
depth.emplace_back(d);
for (int v : adj[u]) {
if (v == p) continue;
dfs(v, u, d + 1);
euler_path.emplace_back(u);
depth.emplace_back(d);
}
}
void precompute_log() {
M = euler_path.size();
lg.assign(M + 1, 0);
for (int i = 2; i <= M; ++i) lg[i] = lg[i / 2] + 1;
}
void build_block() {
block_size = max(1, lg[M] / 2);
block_cnt = (M + block_size - 1) / block_size;
block.assign(block_cnt, 0);
mask.assign(block_cnt, 0);
for (int i = 0, j = 0, b = 0; i < M; ++i, ++j) {
if (j == block_size) j = 0, ++b;
if (j == 0 || depth[i] < depth[block[b]]) block[b] = i;
if (j > 0 && (i >= M || depth[i] > depth[i - 1])) mask[b] += 1 << (j - 1);
}
}
void build_sparse_table() {
table_size = lg[block_cnt] + 1;
st.assign(block_cnt, vector<int>(table_size));
for (int i = 0; i < block_cnt; ++i) st[i][0] = block[i];
for (int j = 1; j < table_size; ++j) {
for (int i = 0; i < block_cnt; ++i) {
int ni = i + (1 << (j - 1));
if (ni >= block_cnt)
st[i][j] = st[i][j - 1];
else
st[i][j] = depth[st[i][j - 1]] < depth[st[ni][j - 1]] ? st[i][j - 1]
: st[ni][j - 1];
}
}
}
void precompute_in_block_RMQ() {
ways = 1 << (block_size - 1);
in_block_RMQ.assign(ways, vector<vector<int>>());
for (int i = 0; i < block_cnt; ++i) {
if (!in_block_RMQ[mask[i]].empty()) continue;
in_block_RMQ[mask[i]].assign(block_size, vector<int>(block_size));
for (int j = 0; j < block_size; ++j) {
in_block_RMQ[mask[i]][j][j] = j;
for (int k = j + 1; k < block_size; ++k) {
in_block_RMQ[mask[i]][j][k] = in_block_RMQ[mask[i]][j][k - 1];
int idx = i * block_size + k;
if (idx < M &&
depth[idx] < depth[i * block_size + in_block_RMQ[mask[i]][j][k]])
in_block_RMQ[mask[i]][j][k] = k;
}
}
}
}
void build() {
dfs();
precompute_log();
build_block();
build_sparse_table();
precompute_in_block_RMQ();
}
int query(int u, int v) {
u = first_vis[u], v = first_vis[v];
if (u > v) swap(u, v);
int u_block = u / block_size, v_block = v / block_size,
u_offset = u % block_size, v_offset = v % block_size;
if (u_block == v_block)
return euler_path[u_block * block_size +
in_block_RMQ[mask[u_block]][u_offset][v_offset]];
int mn1 = u_block * block_size +
in_block_RMQ[mask[u_block]][u_offset][block_size - 1];
int mn2 = v_block * block_size + in_block_RMQ[mask[v_block]][0][v_offset];
int lca = depth[mn1] < depth[mn2] ? mn1 : mn2;
if (u_block + 1 < v_block) {
int sz = lg[v_block - u_block - 1];
int mn3 = st[u_block + 1][sz], mn4 = st[v_block - (1 << sz)][sz];
int mn = depth[mn3] < depth[mn4] ? mn3 : mn4;
lca = depth[lca] < depth[mn] ? lca : mn;
}
return euler_path[lca];
}
};
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int N, Q;
cin >> N >> Q;
LCA lca;
lca.init(N);
for (int i = 2; i <= N; ++i) {
int p;
cin >> p;
lca.add_edge(i, p);
}
lca.build();
for (int i = 0; i < Q; ++i) {
int u, v;
cin >> u >> v;
cout << lca.query(u, v) << "\n";
}
return 0;
}
這個方法常數很高,比賽中並不實用,但是個很漂亮的做法可以達到理論上最佳的時間複雜度。
Exercises
我們來看一些可以使用 LCA 來解的例題。
給定一棵有 \( N \) 個節點的樹,你的任務是要處理以下形式的 \( Q \) 次詢問:
給定 \( a \) 和 \( b \),請輸出點 \( a \) 到點 \( b \) 的最短路徑的距離為何。
\( N,\ Q \leq 2 \times 10^5 \)
Solution
這題是經典的求樹上兩點距離的問題。已知對於任意點對 \( (u,\ v) \),\( LCA(u,\ v) \) 必定會位於點 \( u \) 到點 \( v \) 的最短路徑上。因此針對查詢點對 \( (a,\ b) \),我們可以先找出 \( LCA(a,\ b) \),然後利用點 \( a \) 的深度加上點 \( b \) 的深度,最後再減去兩倍的 \( LCA(a,\ b) \) 的深度,即為點 \( a \) 到點 \( b \) 的距離。
CF 519E - A and B and Lecture Rooms
題意為給定一棵有 \( N \) 個節點的樹,你的任務是要處理以下形式的 \( Q \) 次詢問:
給定 \( a \) 和 \( b \),請輸出樹上有多少點 \( i \) 滿足點 \( a \) 到點 \( i \) 的距離等於點 \( b \) 到點 \( i \) 的距離。
\( N,\ Q \leq 10^5 \)
Solution
以下我們可以分成四種 Case 來討論:
- \( a \) 等於 \( b \)
- 點 \( a \) 到點 \( b \) 的距離為奇數
- 點 \( a \) 到點 \( b \) 的距離為偶數且中點為 \( LCA(a,\ b) \)
- 點 \( a \) 到點 \( b \) 的距離為偶數但中點不為 \( LCA(a,\ b) \)
對於 Case 1,很明顯答案會是 \( N \)。
對於 Case 2,觀察後我們可以發現樹上沒有任何點可以滿足題目要求,所以答案會是 \( 0 \)。
對於 Case 3,假設點 \( A \) 和點 \( B \) 為 \( LCA(a,\ b) \) 的小孩且兩點分別為點 \( a \) 和點 \( b \) 的祖先。我們可以發現從 \( LCA(a,\ b) \) 出發往非點 \( A \) 和點 \( B \) 的方向走的話,能到達的所有點均能滿足題目要求。因此,答案會是 \( N \) 減去以點 \( A \) 為根的子樹大小和以點 \( B \) 為根的子樹大小。
對於 Case 4,假設點 \( i \) 為點 \( a \) 和點 \( b \) 的距離中點且點 \( b \) 的深度較點 \( a \) 深。我們可以發現從點 \( i \) 出發往非點 \( p \) 和點 \( B \) 的方向走的話,能到達的所有點均能滿足題目要求(這邊點 \( p \) 為點 \( i \) 的父節點,點 \( B \) 為點 \( i \) 的小孩且同時為點 \( b \) 的祖先)。因此,答案會是以點 \( i \) 為根的子樹大小減去以點 \( B \) 為根的子樹大小。
CF 609E - Minimum spanning tree for each edge
給定一張有 \( N \) 個點和 \( M \) 條帶權重邊的連通無向圖,圖中沒有自環及重邊。你的任務是要針對圖中的每一條邊,輸出有包含到該邊的 minimal spanning tree 的權重。
\( N \leq 2 \times 10^5 \)
\( N-1 \leq M \leq 2 \times 10^5 \)
Solution
根據題意,我們可以分成兩個 Case 來討論。對於 Case 1,如果給定的邊已經位於該圖的最小生成樹上,那麼我們就直接輸出最小生成樹的權重。而對於 Case 2,如果給定的邊不位於最小生成樹上,那麼我們就需要先將給定的邊加入到最小生成樹中,假設給定邊的兩端點為點 \( u \) 和點 \( v \)。加入的同時,給定邊會和點 \( u \) 到點 \( v \) 的最短路徑組合起來形成環。而為了要取 minimal 且維持樹的結構,我們需要移除環上權重最大的邊,這條邊不會是給定的邊,否則給定的邊會符合 Case 1。因此針對 Case 2,我們需要找到點 \( u \) 到點 \( v \) 最短路徑上權重最大的邊。
關於為什麼這樣做會給我們 minimal 的結果,有興趣的讀者可以參考本文附上的參考資料1。
而針對如何找到點 \( u \) 到點 \( v \) 最短路徑上權重最大的邊,我們可以利用 \( LCA(u,\ v) \) 將最短路徑拆分成兩條路徑,所求即為兩條路徑上權重最大值的最大值。搭配上 binary lifting 的想法,在預處理點 \( u \) 的第 \( 2^i \) 個祖先是誰的同時,我們可以多預處理從點 \( u \) 到點 \( u \) 的第 \( 2^i \) 個祖先路徑上最大的權重,遞迴關係式如下:
$$maxWeight(u,\ i) = \begin{cases} w(u,\ parent(u)) & \text {$i = 0$} \newline max(maxWeight(u,\ i-1),\ maxWeight(ancestor(u,\ i-1),\ i-1)) & \text{$i > 0$} \end{cases}$$
這邊 \( maxWeight(u,\ i) \) 代表點 \( u \) 到點 \( u \) 的第 \( 2^i \) 個祖先路徑上最大的權重,\( w(u,\ parent(u)) \) 則代表點 \( u \) 和其父節點連邊的權重。
有了該資訊,我們就可以在 \( O(\log N) \) 的時間內得知最小生成樹上兩點最短路徑的最大權重。而針對 Case 2,我們輸出的答案就會是最小生成樹的權重減去給定邊兩端點樹上最短路徑的最大權重,最後再加上給定邊的權重。
Sample Code
#include <bits/stdc++.h>
using namespace std;
struct DSU {
vector<int> par, size;
void init(int n) {
par.assign(n + 1, 0);
size.assign(n + 1, 1);
iota(par.begin(), par.end(), 0);
}
int find(int x) { return x == par[x] ? x : par[x] = find(par[x]); }
bool joint(int u, int v) { return find(u) == find(v); }
void unite(int u, int v) {
u = find(u), v = find(v);
if (size[u] > size[v]) swap(u, v);
par[u] = v;
size[v] += size[u];
}
};
struct LCA {
int time = 0, logN;
vector<int> tin, tout, depth;
vector<vector<pair<int, int>>> adj;
vector<vector<int>> anc, mx;
void init(int n) {
logN = __lg(n);
anc.assign(n + 1, vector<int>(logN + 1, 0));
mx.assign(n + 1, vector<int>(logN + 1, 0));
tin.assign(n + 1, 0);
tout.assign(n + 1, 0);
depth.assign(n + 1, 0);
adj.assign(n + 1, vector<pair<int, int>>());
}
void add_edge(int u, int v, int w) {
adj[u].emplace_back(w, v);
adj[v].emplace_back(w, u);
}
void dfs(int u = 1, int p = 0) {
tin[u] = ++time;
anc[u][0] = p;
for (int i = 1; i <= logN; ++i) {
anc[u][i] = anc[anc[u][i - 1]][i - 1];
mx[u][i] = max(mx[u][i - 1], mx[anc[u][i - 1]][i - 1]);
}
for (auto& pr : adj[u]) {
int w = pr.first, v = pr.second;
if (v == p) continue;
depth[v] = depth[u] + 1;
mx[v][0] = w;
dfs(v, u);
}
tout[u] = ++time;
}
void build() {
dfs();
tout[0] = ++time;
}
bool is_ancestor(int u, int v) {
return tin[u] <= tin[v] && tout[v] <= tout[u];
}
int get_max(int u, int d) {
int res = 0;
for (int i = 0; i <= logN; ++i)
if (d & 1 << i) {
res = max(res, mx[u][i]);
u = anc[u][i];
}
return res;
}
int query_lca(int u, int v) {
if (is_ancestor(u, v)) return u;
if (is_ancestor(v, u)) return v;
for (int i = logN; ~i; --i)
if (!is_ancestor(anc[u][i], v)) u = anc[u][i];
return anc[u][0];
}
int query_max(int u, int v) {
int LCA = query_lca(u, v);
int mx1 = get_max(u, depth[u] - depth[LCA]);
int mx2 = get_max(v, depth[v] - depth[LCA]);
return max(mx1, mx2);
}
};
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int n, m;
cin >> n >> m;
vector<array<int, 3>> edges, queries;
for (int i = 0; i < m; ++i) {
int u, v, w;
cin >> u >> v >> w;
if (u > v) swap(u, v);
edges.push_back({w, u, v});
queries.push_back({w, u, v});
}
sort(edges.begin(), edges.end());
set<array<int, 2>> spanning_tree;
long long ans = 0;
DSU dsu;
LCA lca;
dsu.init(n);
lca.init(n);
for (auto& e : edges) {
int w = e[0], u = e[1], v = e[2];
if (dsu.joint(u, v)) continue;
dsu.unite(u, v);
ans += w;
spanning_tree.insert({u, v});
lca.add_edge(u, v, w);
}
lca.build();
for (auto& q : queries) {
int w = q[0], u = q[1], v = q[2];
if (spanning_tree.find({u, v}) != spanning_tree.end()) {
cout << ans << "\n";
continue;
}
cout << ans - lca.query_max(u, v) + w << "\n";
}
return 0;
}
Summary
在本文當中,我們整理了五種常見的尋找樹上最近共同祖先的方法,分別為:
- 預處理 \( O(N) \)、每次查詢 \( O(N) \) 的暴力作法。
- 預處理 \( O(N\log N) \)、每次查詢 \( O(\log N) \) 的倍增法。
- 強制離線 \( O((N+Q)\alpha(N)) \) 的 Tarjan's offline algorithm。
- 利用樹鏈剖分的相關操作達到預處理 \( O(N) \)、每次查詢 \( O(\log N) \) 的作法。
- \( O(N) \) - \( O(1) \) LCA
以時間複雜度來看,\( O(N) \) - \( O(1) \) LCA 的作法應該會是所有作法當中最快的。但由於其實作複雜、常數過大,實際跑起來的速度跟其他做法相比並不會相差太多,單純只有理論上的意義。筆者自己比較喜歡使用倍增法來解決 LCA 的相關問題,因為實作上比較簡單,而且想法上也比較直覺。對於大部分 LCA 問題的 problem size 來說,每次查詢 \( O(\log N) \) 也算跑得過,因此滿推薦讀者們可以使用倍增法。
References
- Lowest Common Ancestor - O(sqrt(N)) and O(log N) with O(N) preprocessing
- Lowest Common Ancestor - Binary Lifting
- Lowest Common Ancestor - Tarjan's off-line algorithm
- Lowest Common Ancestor - Farach-Colton and Bender Algorithm
- 解决 LCA 问题的三种算法
- 最近公共祖先 - OI Wiki
- Tree - 演算法筆記
- Range Minimum Query and Lowest Common Ancestor
- LCA problems
- 圖論進階